R言語によるSVM体験の学習目標と概要
学習目標
- SVMの仕組みと利用について説明できる
- R言語を利用してサンプルデータで学習分類器を構成し,サンプルデータの一部を分類した上で,学習分類器の精度について説明できる
概要
SVMとは
SVMはSupport Vector Machineの略で,書籍などでは「サポートベクトルマシン」と記述されています.SVMは,いくつかのグループに区別されたデータをもとに,未知のデータがどのグループのものであるかを予測する機械学習手法です.特徴として,すでに区別されたデータを必要とすることが挙げられます.例えば,ゴールデンレトリバーという犬と他の犬種の体高,胴の長さ,足の長さ,耳の長さ,体重を測定したデータがあって,それらのデータをコンピュータに学習させて,学習させたコンピュータに未知の犬のデータを入力して,ゴールデンレトリバーであるか否かの判定結果を得ます.このように事前に分類されたデータを用いる機械学習のことを教師あり学習(supervised learning)といいます.統計の分析手法にあった回帰分析に似ていますね.回帰分析はすでに測定された目的変数を他の説明変数から予測する回帰式を導出する分析でした.
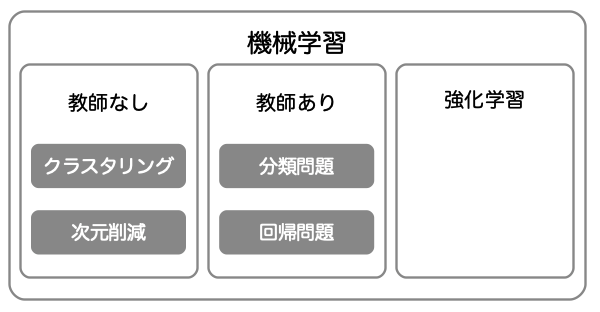
SVMのように,どのグループに属するか不明なデータに対して,どのグループに属するか判定する問題を「分類問題」といいます.機械学習で扱う問題は「分類問題」「回帰問題」「次元削減」「クラスタリング」の4つに区分されます(参考:scikit-learn algorithm cheat-sheet).
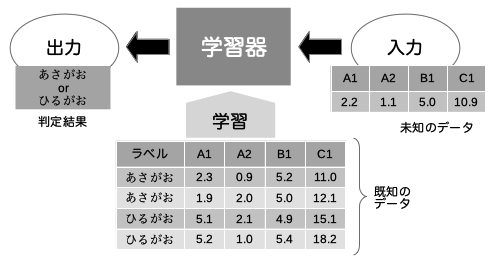
分類問題に対して解を与える手法は何もSVMに限りません.前述のようにSVMでは,ずでに分類されたデータを学習するコンピュータがあり,そのコンピュータに未知のデータを入力すると,分類の判定結果を返します.このように既に分類を知っているデータ(既知データ)をもとに判定のためのルールを学習するコンピュータのことを学習器と呼びます.目に見えるものがあるわけではありませんが,SVMの場合,既知データを使って学習器を作成し,その学習器に未知のデータを入力すると,学習器が判定結果を出力します.このときの学習器を作成する方法は様々あり,その1つがSVMです.