タスクML-1_"R言語でSVMを体験する"
R言語プログラム[1]がもつアヤメのデータのセット(データセット)を使って,「分類問題」を体験します.R言語には,練習用にたくさんのデータセットが含まれています(Documentation for package ‘datasets’ ).アヤメのデータは,3種類類のアヤメ(setosa,versicolor,virginica)のデータを含みます.3種類のアヤメのそれぞれ50本のデータで,各データは,がく片(sepal)と花弁(petal)のそれぞれの長さと幅の数値から構成されます.がく片(sepal)と花弁(petal)をイメージできないという人はWikipediaの「萼(がく)」のページに写真があるので見てみてください.
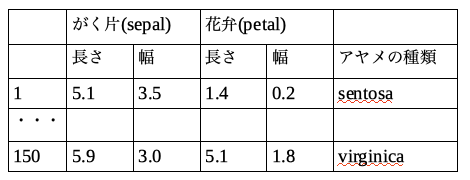
ここでの体験は,SVMを使って,がく片と花弁の数値からアヤメの種類を判定するという体験です.SVMは,いくつかのグループに区別されたデータをもとに,未知のデータがどのグループのものであるかを予測する機械学習手法です.アヤメのデータで考えると,「アヤメの種類」がグループ分けになります.「アヤメの種類」が分かっているデータを使って,学習器を作り,アヤメの種類はわからないが,がく片と花弁の長さと幅の数値から「アヤメの種類」を予測することを目指します.どういう仕組みで判定されるかは,演習を進めながら理解していきましょう.
アヤメのデータを2つに分けます.ひとつは,コンピュータが学習するためのデータです.これを教師データまたはトレーニングデータ(training data)と呼びます.もうひとつは,アヤメの種類がわからないデータです.実際にはアヤメの種類は分かっていますが,わからないという設定で進めます.この判定されていないデータのことを,いまはテストデータ(test data)と呼びます.いまから扱うデータは,3種類のアヤメの50本ずつのデータなので,全部で150個(3種*50本)のデータです.150のデータを2つに分けます.ひとつはトレーニングデータで,もうひとつはテストデータです.
ここから先は R notebook を利用して次の手順でSVMによる分類を体験します.
- R notebookの基本
- データセットirisの確認
- トレーニングデータとテストデータの生成
- SVMの体験
- SVMによる結果の評価と感想を共有しよう
- SVMの利用イメージを投稿しよう
次の演習に取り組んでください.
[演習] アヤメのデータを確認する
この演習用にR notebookのファイル「Task-ML-1.ipynb」を提供します.ファイル「Task-ML-1.ipynb」をダウンロードし,https://rnotebook.ioの環境で開き,演習に取り組んでください.https://rnotebook.ioの環境で,R notebookのファイル「Task-ML-1.ipynb」を開いて,次の(1)から(6)を確認してください.操作方法はR notebookのファイル「Task-ML1.ipynb」に記述しています.
[注意1] R notebookのファイル「Task-ML-1.ipynb」をダウンロードするには,下のリンク「Task-ML-1.ipynb」を右クリック(Ctrlキー+クリック)して,「別名でリンク先を保存」を選び,適当な保存場所に保存してください.
[注意2] https://rnotebook.ioの環境構築は,「Jupyter R notebookの作成方法」の(1)(2)を参照してください.
[注意3] R notebookのファイル「Task-ML1.ipynb」をhttps://rnotebook.ioの環境で開く方法は,「Jupyter R notebookのファイルを利用する方法」を参照してください.
演習用ファイル:Task-ML-1.ipynb
(プレカンファレンス用 https://rnotebook.io/anon/e162193bc3cda157/notebooks/Task-ML-1.ipynb# )
(1) R notebookの基本
(2) データセットirisの確認
(3) トレーニングデータとテストデータの生成
(4) SVMの体験
(5) SVMによる結果の評価と感想を共有しよう
(6) SVMの利用イメージを投稿しよう